
Creating Your Own Olympics Schedule with Web Scraping
February 10, 2022 - Automation, Fun & Games
January 11, 2026: This post is extremely outdated and the code is no longer working. I tried updating a few parts but it's not worth the effort. Keeping this here for posterity and because the techniques still work in general and might be helpful to someone.
Personal Update: Before I hop into this post I wanted to share that I am returning to writing after a bit of a holiday break and hiatus. In that time, I have left Tableau and started a new role at an awesome startup. Tableau holds a special place in my heart so I will definitely continue to write a mix of Tableau and non-Tableau content. Keep an eye out for my next Tableau-related post on creating a Web Data Connector with OAuth and CORS! As always, feel free to send me a request if you want me to dive into a specific topic!
Is anyone else frustrated with the Olympics website? 🙄😒 I feel like I have to go to 5 different pages to find what I am looking for and it isn't always displayed in order and doesn't always show the information I want in one place. Well obviously I was feeling frustrated, hence the writing of this post, and so I decided to scrape the Olympics website and put together a quick and dirty app that would help me find and save what I was interested in. This post is not going to go over every single line of code but I wanted to share my approach on how I went about creating this app. Plus, you are free to use it yourselves as well!
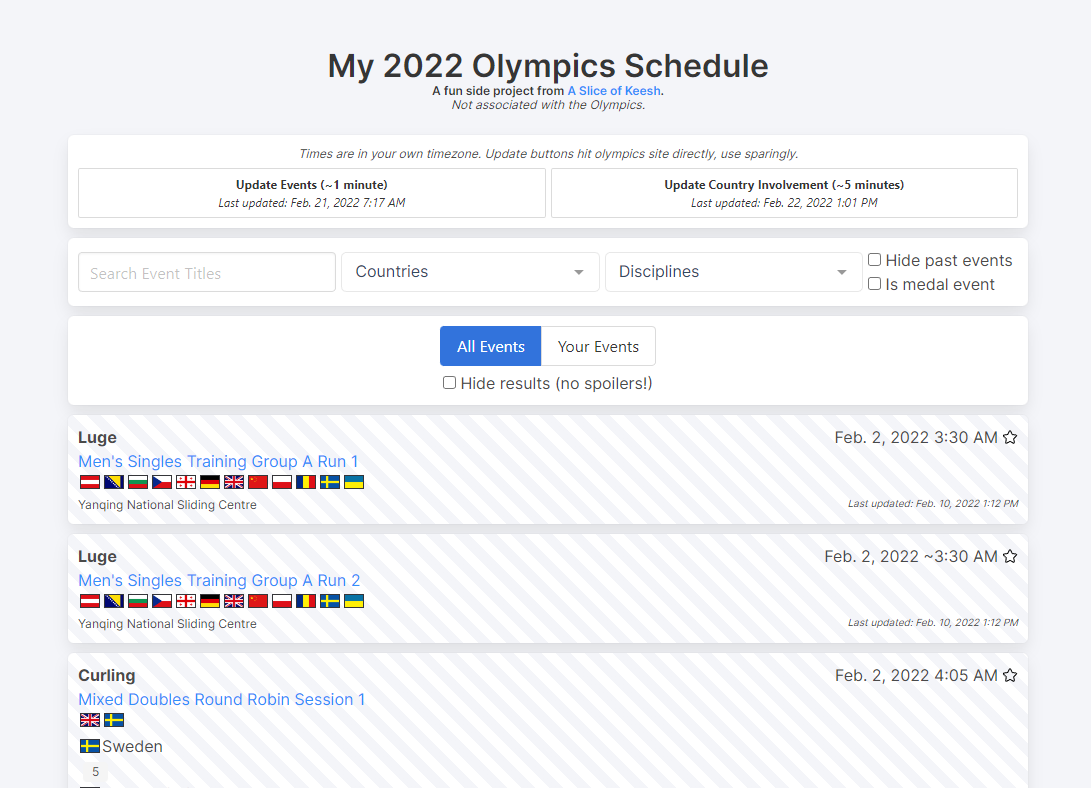
A couple of disclaimers: This app is in no way associated with the Olympics or the Olympics.com site, it's just a personal project. This app is just the bare bones of what I personally wanted to see and could definitely be improved but since this event happens for only a couple of weeks it felt like enough. This app was not written in the most efficient way (I found many places I would refactor and improve it just while writing this post😅). Check out the code and feel free to fork your own version and add cool new features!
Project Setup
To set this project up I started with a blank Express app. You can fork my starter template for your own project or run it in CodeSandbox. I knew I would need a way to store the Olympics data since I wasn't planning on scraping the page every time you opened the app. For this, I used lowdb, a nice little JSON database great for small projects like this one. I also needed a way to parse the HTML returned from the Olympics website in Node.js so I use node-html-parser which is nice because you can use methods like getElementsByTagName or querySelector to pull out what you need. I created a quick helper function that allowed me to get any page and parse it with this package:
async function getPage(url) {
const response = await fetch(url);
const body = await response.text();
const document = HTMLParser.parse(body);
return document;
}
Once I had my tools in place, it was time to tackle how I was going to go about getting the data!
Where to begin?
Before I began coding anything I had to figure out how data was being displayed on the Olympics site and then map out how I wanted to go about getting that data. After browsing the Olympics.com website I originally thought I would be able to simply scrape each day's page and grab all the event data for that day across all disciplines for that day. No biggie right?! Wrong! If you open up one of the day schedules in developer tools or with inspect element, you will see two things. First, the data for the events are not actually on the page! It is being loaded from other HTML pages, so if you try to scrape the day page you won't see any event information. Secondly, there is a different separately loaded HTML page for each discipline + day combination! Because of this, I had to take another approach. Looking back on it now there is a better way to do this (which I implemented later on when looking at country data) but this is how I went about approaching it.
Getting the overall schedule
Since I now knew that I needed to scrape each discipline + day combination's HTML page, I had to figure out which days each discipline had events going on. To do that I looked at the overall schedule page. (I now realize I could have just looked at the script that was pulling each HTML page from the individual day pages instead, oh well!) On this page, I was able to see what days each discipline had events at a glance. This was a great place to start as it acted as a guide for the rest of my scraping. By scraping this page I was able to create a scaffolding that told me where to find the information for each discipline on each day. To do this I created an updateOverallSchedule endpoint that grabbed the overall schedule page and parsed it. If you open the schedule page and "inspect element" or open up dev tools you will see that it is just a table that has images in each cell whenever there is an event for each discipline. Once I grabbed the page data I first started out by getting the table and rows:
const htmlTable = document.querySelector("table.table-calendar");
const rows = htmlTable.querySelectorAll("tr");
I then went through each day number that was in the header of the table (<th> tags) and pulled out each number. Lucky for me the entirety of Olympic events happens within February and so for this whole project, I just treated each day as a number from 2 through 20. #QuickAndDirty! I built out an object where each key was a day with an empty array I could then populate with more info.
let schedule = {};
const days = rows[1].querySelectorAll("th");
for (let day of days) {
const dayNum = day.innerText.trim();
schedule[dayNum] = [];
}
Next, I wanted to grab the discipline names and put them in the appropriate arrays. Here I noticed that not every row had the data I was looking for so I used the CSS class of the objects as a way to filter what I wanted. For example: row.classList && (row.classList.contains("Res1") || row.classList.contains("Res2")) looks for any table row that has a class and one of those classes is either Res1 or Res2. I did the same for pulling out the discipline name as those cells had the class .text-left so I could easily pull out the innerText of the cell and get the discipline name. Then I looped through each column in the row to see which days the discipline had events. For each column, I grabbed the <img> element. If there was no image element, then I skipped that column and did not add the discipline to that day. Otherwise, I pulled the source of the image and pulled out the name. This is because each discipline + day combination has an image that shows if there are medal events that day and I wanted to know that information (even though I ended up not needing it.)
const image = occurances[index].querySelector("img");
if (image) {
const type = image.attributes.src
.split("/")
[image.attributes.src.split("/").length - 1].replace(".png", "");
// ...
}
Finally, I crafted the link for that particular day and discipline that I would use to scrape each combination's details. For this I inspected one of the discipline + day HTML pages and saw that there was a simple pattern: https://olympics.com/beijing-2022/olympic-games/en/results/<discipline-name-here>/zzzs058b-date=<date-here>.htm. Therefore I simply replaced the spaces in each discipline with an underscore and made them lowercase, and added in the day I was looking at to create the link where I could find more data.
const date = ("0" + day.toString()).slice(-2);
const disciplineLink = discipline.replace(/ /g, "-").toLowerCase();
let link = `https://olympics.com/beijing-2022/olympic-games/en/results/${disciplineLink}/zzzs058b-date=2022-02-${date}.htm`;
I pushed all of this into the matching array in my schedule object.
schedule[day].push({ discipline, type, link });
And finally, save the entire object in my lowdb database:
db.set("overallSchedule", schedule).write();
It ended up looking something like this:
{
"2": [
{
"discipline": "Curling",
"type": "day",
"link": "https://olympics.com/beijing-2022/olympic-games/en/results/curling/zzzs058b-date=2022-02-02.htm"
},
{
"discipline": "Luge",
"type": "day",
"link": "https://olympics.com/beijing-2022/olympic-games/en/results/luge/zzzs058b-date=2022-02-02.htm"
}
],
"3": [
{
"discipline": "Alpine Skiing",
"type": "day",
"link": "https://olympics.com/beijing-2022/olympic-games/en/results/alpine-skiing/zzzs058b-date=2022-02-03.htm"
},
{
"discipline": "Curling",
"type": "day",
"link": "https://olympics.com/beijing-2022/olympic-games/en/results/curling/zzzs058b-date=2022-02-03.htm"
}
// ...
]
// ...
}
Now I had my path for scraping all the event data!
Getting each day's information
Now that I had a path to follow, I could start scraping the events for each discipline + day combination. For this, I created a new endpoint /updateDay/:day (where :day is the number day) that would update one day's (Beijing time) events. For the selected day I pulled up the disciplines and links and looped through each page. I started looking at each of the discipline + day HTML pages to see if there were similarities between the different types of events. I originally thought I would need separate parsing methods for each type of event or even each discipline + day combo but thankfully I ended up being able to create one parsing function to rule them all. (This is why I have a whole separate file called parse.js and it only contains one function called A. I had planned to create a suite of different parsing methods but it wasn't necessary.) This parsing function needed to grab each of the different details for each event such as venue, time, event name, and winning country (if there was one). Thankfully each of these pages (example) is simply a table with the information so I could go through each row (an event) and grab what I needed. Let's take a look at each piece of the parse.A function.
After parsing and grabbing the table rows as an array I looped through each one and realized I wanted some way of uniquely identifying each event. Not only was this just generally good practice but it was necessary for some of the later steps I wanted to do (matching country involvement, and creating your own schedule). At first, I found an ID in the data of the row for each event:
<tr
class="clickable-schedule-row "
sport="CCS"
data-url="../../../en/results/cross-country-skiing/results-women-s-sprint-free-qual-000100-.htm"
rsc="CCSWSPRINT------------QUAL000100--"
></tr>
In this example it was CCSWSPRINT------------QUAL000100-- but this later turned out to not be reliable. Instead, I decided to go with each event's link, since for each and every event there is a page that shows the results. I was able to grab this from the data-url attribute of the table row for the event.
const id = row.attributes["data-url"];
Next, I wanted to get the time of the event. This was relatively straightforward since there was a CSS class called schedule-time-data I could use to pull out the element that showed the start time. This pattern also happened for some of the other items I was gathering which was very handy! One thing to note is that not all events have an exact start time, some start whenever the previous event finishes. For easier sorting and filtering I decide to keep track of the time (since they were displayed in order) and if I found an event without an exact time I just used the previous time.
const scheduledEvent = row.querySelector("span.schedule-time-data");
let startTime;
if (scheduledEvent) {
startTime = row.querySelector("span.schedule-time-data").attributes["full-date"];
previousTime = startTime;
} else {
startTime = row.querySelector("small").innerText.trim() + " | " + previousTime;
}
The next few pieces of data were generally easy to get. For the venue, there was an element with the class schedule-venue I could grab the text from. For the title, there is only one link in each event's row and it holds the title of the event so I used the <a> tag to find it. (You'll see I also grabbed the link, this was before I changed the ID method). For some events, like Ice Hockey, there is a game number so if it existed I grabbed it. This one was a little trickier since there was no special class so I just tried to find a way to identify the cell with the data. Next each event that awarded medals had a medal icon image so I looked for that image and if it existed I saved that as a boolean. Then I grabbed the status of the event from the table cell with the schedule-status class.
const venue = row.querySelector("td.schedule-venue").innerText.trim().replace("&", "&");
const title = row.querySelector("a").innerText.trim();
const link = row.querySelector("a").attributes.href;
const gameNum = row.querySelector("div.flex-grow-1 + div")
? row.querySelector("div.flex-grow-1 + div").innerText.trim()
: "";
const medalEvent = row.querySelector("img.medal") !== null;
const status = row.querySelector("td.schedule-status").innerText.trim();
Getting the results (if there were results) was a bit more involved. This was because the table layout changed based on if it was a medal event or not and if the event had happened yet or not. The main things to look at here are the country name which I got from a <div> with the class playerTag:
const country = resultRow.querySelector("div.playerTag").attributes.country;
The result, if there was a numerical score:
const result = resultRow.querySelector("div.result")
? resultRow.querySelector("div.result").innerText.trim()
: null;
And the medal status if medals were awarded:
const medal = resultRow.querySelector("div.MedalBoxSmall>img").attributes.alt;
Once I had all the pieces of data from the page I wanted, I pushed them all into an object. Finally, within the endpoint, I added some more data to each event like the name of the discipline, the day, and the timestamp for when it was updated. I also added a blank array for each newly created event called countriesInvolved. This was because as I was going through the pages I realized they did not contain information about which countries were involved unless it was a head-to-head match. This meant I needed to scrape more data to be able to filter the events by the countries involved. This leads us to the next step!
Getting the countries
For some events, it is a head-to-head matchup so the names of the countries are listed on the events page, however, for many of the events, there are multiple countries competing at once and for those events, I needed some more data. So at this point, I started digging into the country schedule pages (example) where I was able to see which events each country would be participating in. Now I needed to scrape each country's schedule page which of course, as you might have guessed, was also made up of individual HTML pages. For this part, I created a new endpoint called updateNOCList. To start, I wanted a list of all the countries (technically NOCs.) Again I created a scaffolding object to hold this information by scraping the NOC overview page. Each country had a <div> that I could grab with a p-2 class.
const container = document.querySelector("div.contanier-fluid>div.row");
const countryDivs = container.querySelectorAll("div.p-2");
I was then able to pull out the information I needed starting with the country's three-letter ID by looking at the country attribute. Next, I use the inner text of each div to get the full country name. And finally, I used the link to the country's page to get its slug, which is just how the country is written in URLs. (Example "United States of America" is turned into united-states for URLs.)
const id = countryDiv.attributes.country;
const name = countryDiv.innerText.trim();
const countryHref = countryDiv.querySelector("a").attributes.href;
const slug = countryHref
.split("/")
[countryHref.split("/").length - 1].replace("noc-entries-", "")
.replace(".htm", "");
You might notice in the code that I also built out all the possible day links for each country. I originally thought I could just go through all possibilities for each country + day combination but this ended up taking waaay too much time since the Olympics website always returned a page and then I would try and parse it each time. You'll see how I went about getting the links in the next section!
Getting country involvement data
Now that I had my path to follow I could start scraping each country's data and appending it to my list of events. You can find this part in my /updateNOCInvolvement/:NOC endpoint (where :NOC represents a single country). The process for this part of the scraping was pretty similar to the previous section but the big difference here is that I was a bit smarter about how I figured out the links to scrape. Instead of trying to scrape all possible combinations of country and day I scraped the country's overall schedule page and grabbed their <script> snippets that were pulling in the other HTML pages. This meant that as the country's page was updated I would automatically catch any new event involvement without having to scrape every single country + day combination. So first I'm grabbing the country's schedule page using the slug I gathered previously and then finding each instance of a <div> that has an attribute called ddate. These are the divs where I found the scripts pulling in the other event pages.
const baseUrl = `https://olympics.com/beijing-2022/olympic-games/en/results/all-sports/noc-schedule-${NOCSlug}.htm`;
const baseDocument = await getPage(baseUrl);
const dateDivs = baseDocument.querySelectorAll("div[ddate]>script");
I then used some RegEx to grab what I needed and I could then loop through and parse each page for each day a country was involved in an event.
const r = new RegExp(/en\/results\/all-sports\/(.*).htm/);
This time however since I already had the actual event information, all I really needed to know was which events the country was involved in. So instead of parsing the whole table again for the events. I simply looked for each row that had an event link (which I am using as an ID) and matched it with an event I already had in my database.
const id = event.attributes["data-url"];
const foundEvent = db.get("events").find({ id: id }).value();
Once I found a match, I then just added the country ID to the event's countriesInvolved array using a new Set to make sure it was a unique list.
if (foundEvent) {
let countriesInvolved = new Set(foundEvent.countriesInvolved);
countriesInvolved.add(NOCID);
countriesInvolved = [...countriesInvolved];
db.get("events").find({ id: id }).assign({ countriesInvolved }).write();
}
At this point, I had a way to get all the event data and populate each event with a list of countries that were involved. Now it was time to build the display!
Displaying the data
I won't dig into this part too much (of course you can take a look at all the code in my repo!) but I wanted to highlight some of the main features. First I used Vue.js to create a dynamic display of the event data. I started by grabbing the data from my database and creating a div for each event with all the data I had collected. I then added filter options at the top that allowed you to filter by country and discipline, search for event titles, show or hide past events, and show only medal events.
// Filter countries
const selectedCountriesIDs = this.selectedCountries.map((c) => c.value);
if (selectedCountriesIDs.length > 0) {
events = events.filter((e) => e.countriesInvolved.some((x) => selectedCountriesIDs.includes(x)));
}
I then added a localStorage item that would keep track of your favorites. Each event has a star icon in the top right corner that upon clicking will add or remove an event from your list of favorites. I then added a button so you could flip between seeing all events and only your favorite events.
addFavorite: function (id) {
let favorites = localStorage.getItem("favorites")
? JSON.parse(localStorage.getItem("favorites"))
: [];
favorites.push(id);
favorites = [...new Set(favorites)];
localStorage.setItem("favorites", JSON.stringify(favorites));
this.updateFavorites = !this.updateFavorites;
this.$forceUpdate();
},
I also added an option to hide results as I know many people don't want to be spoiled before they get a chance to watch an event.
const hideResults = localStorage.getItem("hideResults")
? localStorage.getItem("hideResults")
: "true";
Finally, I included two buttons, one to update the events and one to update the country's involvement. This way anyone looking at this page can update the data as needed. (Note, please use this sparingly!)
updateAllNOCInvolvements: async function () {
this.updating = true;
for (let NOC of this.NOCs) {
console.log("Getting", NOC.name);
this.progress = Math.round(
((this.NOCs.indexOf(NOC) + 1) / this.NOCs.length) * 100
);
await this.updateNOCInvolvement(NOC.name);
}
await this.getEvents();
console.log("Complete!");
this.getUpdates();
this.updating = false;
this.progress = 0;
}
Spiced it all up with a little bit of Bulma CSS and a nice multi-select component and my quick and dirty Olympics app was ready to go!
Let me know if you use it (or have suggestions for making it better 😉) in the comments below and subscribe to see what other random fun things I make in the future! Happy Olympics watching! 🎿
Again, this was just a fun exercise in web scraping and not a definitive guide or best way of getting this data. This code is definitely fragile and will likely not work with the next Olympics but hopefully, you learned some tidbits you can apply to other projects!
Subscribe
Sign up to never miss a post!

About Me
Subscribe
Sign up to never miss a post!
Popular Posts
A Quick Tableau Data Source Mapper
July 13, 2021
Spotify Playlist Generator
November 29, 2021Topic Request
Want me to cover a specific topic? Let me know!
Leave a comment